자료구조란 무엇인가? (Data Structure)
- 프로그램에서 사용할 많은 데이터를 메모리 상에서 관리하는 여러 구현 방법들입니다.
- 효율적인 자료구조가 성능 좋은 알고리즘의 기반이 됩니다.
- 자료의 효율적인 관리는 프로그램의 수행 속도와 밀접한 관련이 있습니다.
- 여러 자료 구조 중에서 구현하려는 프로그램에 맞는 최적의 자료구조를 활용해야 하므로 자료구조에 대한 이해가 중요합니다.
자료구조의 종류
- 선형 자료구조
배열 (Array)
선형으로 자료를 관리, 정해진 크기의 메모리를 먼저 할당받아 사용하고, 자료의 물리적 위치와 논리적 위치가 같습니다.
몇 번째 항을 찾가아가는데에 걸리는 시간이 빠릅니다.
자료의 추가/삭제에 드는 비용이 많습니다. 하지만 위치를 알 경우 자료를 꺼내오거나 검색하는 데에 드는 비용은 적습니다.

연결리스트 (LinkedList)
선형으로 자료를 관리, 자료가 추가될 때마다 메모리를 할당받고 자료는 링크로 연결됩니다. 자료의 물리적 위치와 논리적 위치가 다를 수 있습니다.
몇 번째 항을 찾을 때 무조건 맨 처음부터 찾아야 하기 때문에 걸리는 시간이 오래 걸립니다.
자료를 조정하는데에 걸리는 시간은 적지만 위치를 찾는데에 소요되는 시간은 더 많이 걸립니다.
- 리스트에 자료 추가하기

- 리스트에 자료 삭제하기

스택 (Stack)
가장 나중에 입력된 자료가 가장 먼저 출력되는 자료구조 (Last In First Out - LIFO)

큐 (Queue)
가장 먼저 입력된 자료가 가장 먼저 출력되는 자료구조(First In First Out - FIFO)

- 비선형 자료구조
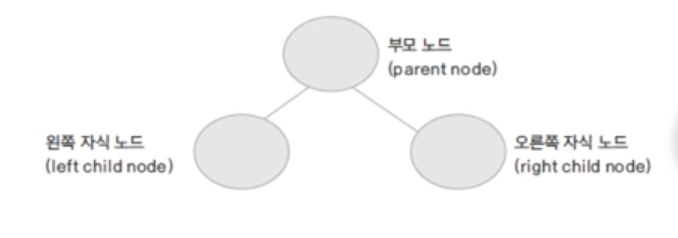
트리 (Tree)
부모 노드와 자식 노드 간의 연결로 이루어진 자료구조

힙 (Heap)
Priority queue를 구현 (우선순위 큐)
- Max heap : 부모 노드는 자식 노드보다 항상 크거나 같은 값을 갖는 경우
- Min heap : 부모 노드는 자식 노드보다 항상 작거나 같은 값을 갖는 경우
- heap 정렬에 활용할 수 있습니다.
이진트리 (Binary Tree)
부모 노드에 자식 노드가 두 개 이하인 트리
이진 검색 트리 (Binary Search Tree)
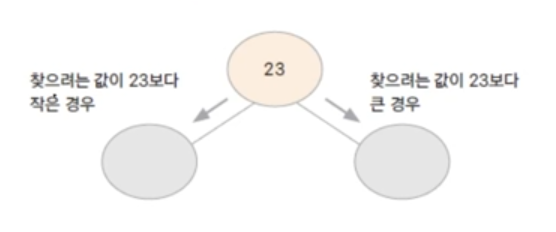
자료(key)의 중복을 허용하지 않습니다. (key는 유일한 값)
왼쪽 자식 노드는 부모 노드보다 작은 값, 오른쪽 자식 노드는 부모 노드모다 큰 값을 가집니다.
자료 검색에 걸리는 시간이 평균 log(n)입니다.
inorder traversal 탐색을 하게 되면 자료가 정렬되어 출력됩니다.
- 예) 23, 10, 28, 15, 7, 22, 56 순으로 자료를 넣을 때

jdk 클래스 : TreeSet, TreeMap (Tree로 시작되는 클래스는 정렬을 지원합니다.)
그래프 (Graph)
- 정점과 간선들의 유한 집합 G = (V, E)
- 정점(vertex) : 여러 특성을 가지는 객체, 노드(node)
- 간선(edge): 이 객체들을 연결 관계를 나타냅니다. 링크(Link)
- 간선은 방향성이 있는 경우와 없는 경우가 있습니다.
- 그래프를 구현하는 방법 : 인접 행렬(adjacency matrix), 인접 리스트(adjacency list)
- 그래프를 탐색하는 방법 : BFS(Bread First Search), DFS(Depth First Search)
- 그래프의 예)

해싱 (Hashing)
- 자료를 검색하기 위한 자료 구조
- 키(key)에 대한 자료를 검색하기 위한 사전(dictionary) 개념의 자료 구조
- key는 유일하고 이에 대한 value를 쌍으로 저장합니다.
- index = h(key): 해시 함수가 key에 대한 인덱스를 반환해주면 해당 인덱스 위치에 자료를 저장하거나 검색하게 됩니다.
- 해시 함수에 의해 인덱스 연산이 산술적으로 가능합니다. O(1)
- 저장되는 메모리 구조를 해시 테이블이라 합니다.
jdk클래스: HashMap, Properties
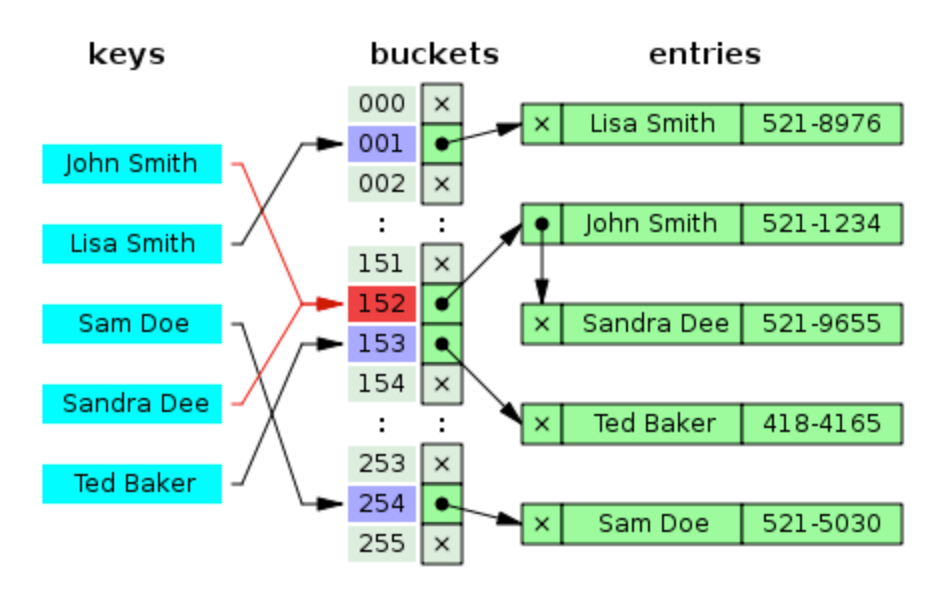
해시 테이블
해시 테이블이란 해시함수를 사용하여 변환한 값을 색인(index)으로 삼아 키(key)와 데이터(value)를 저장하는 자료구조를 말합니다. 기본 연산으로는 탐색(Search), 삽입(Insert), 삭제(Delete)가 있습니다.

버킷과 슬롯
버킷
- 여러개의 슬롯을 저장하는 레코드 형태의 자료 구조입니다.
- 버킷의 갯수는 고정적입니다.
슬롯
- 해시와 매핑되는 값이 저장되어 있는 공간입니다.
- 하나의 버킷 안에는 여러 개의 슬롯이 존재할 수 있습니다.
- 슬롯은 하나이상의 값을 저장할 수 있습니다.
충돌
- 다른내용의 데이터가 같은 키를 갖는 상황입니다.
- 너무 많은 해시 충돌은 해시 테이블의 성능을 떨어뜨립니다.
- 해시함수의 입력값은 무한하지만 출력 값의 가짓수는 유한하므로 해시 충돌은 반드시 발생합니다.
- 클러스터링(Clustering) : 연속된 레코드에 데이터가 몰리는 현상
- 오버플로우(Overflow) : 해시 충돌이 버킷에 할당된 슬롯 수보다 많이 발생하면 더 이상 버킷에 값을 넣을 수 없는 현상
충돌 해결방법
- 체이닝
- 버킷 내에 연결리스트를 할당하여 버킷에 데이터를 삽입
- 해시 충돌이 발생하면 연결 리스트로 데이터들을 연결
- 체이닝의 경우 버킷이 꽉 차더라도 연결 리스트로 계속 늘려가기에 데이터의 주소 값은 바뀌지 않습니다.
참조자료 : https://j3sung.tistory.com/759
'Java' 카테고리의 다른 글
| [JAVA] 자바 - 연결리스트(LinkedList) 구현하기 (0) | 2022.01.04 |
|---|---|
| [JAVA] 자바 - 배열 구현하기 (0) | 2022.01.04 |
| [JAVA] 자바 - Class 클래스 사용하기 (0) | 2022.01.04 |
| [JAVA] 자바 - String, StringBuilder, StringBuffer 클래스, text block (0) | 2021.12.14 |
| [JAVA] 자바 - Object 클래스의 메서드 활용 (0) | 2021.12.14 |